
AI Evals = Software Testing + Data Science
Let’s stop treating AI evals as something entirely new.

AI Evals is a trendy topic.
It’s challenging and exciting because it feels like no one knows exactly how to do it.
But GenAI is magic, right? Just use it to generate test cases, have another model judge the outputs using a rubric written by… yet another model.
The GenAI god will figure it out.
At this point, you probably know where I stand.
If you come from a QA background, AI evals should feel familiar, just with new challenges (and that is where the data science comes in). I have talked in previous posts about the data science skills that are relevant to AI evals. In this post, I walk through a few key concepts from software testing that are particularly relevant to AI evals.
Concepts from Software Testing
Let’s take a closer look at each one of them and how it connects to AI Evals.
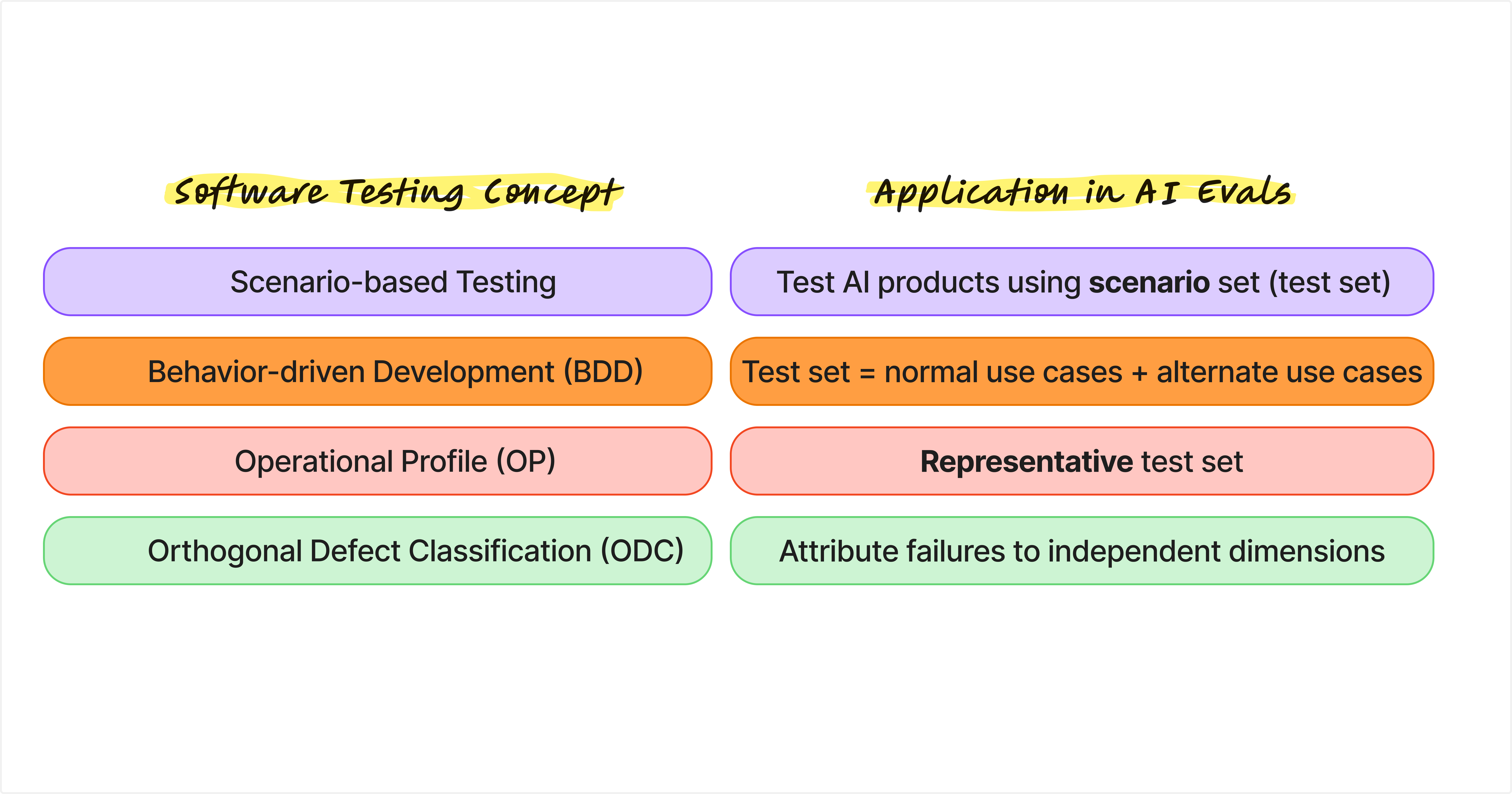
Scenario-based testing
What is it?
Scenario-based testing evaluates software by simulating real-world user workflows and business scenarios to ensure that end-to-end behavior meets user expectations.
Why does it matter?
The test set is central to AI evals. Each data point in a test set is effectively a scenario. For a customer support chatbot, this might mean hundreds of queries that represent our best guesses about what real users would ask in production. In that sense, a test set in AI evals is conceptually the same as a collection of scenarios in scenario-based testing.
Behavior-driven Development (BDD)
What is it?
Behavior-driven Development is an Agile software development methodology that defines application behavior through real-world examples written in natural language.
Why does it matter?
Building test sets can be painful. It is often unclear where to start, especially when cold starting without historical user data. BDD offers a practical approach we can borrow. Start by defining expected application behaviors, enumerate different use cases, and for each one, list the happy path (normal case) as well as unhappy paths (alternate cases). The result is a set of user paths that can be expanded and augmented into a synthetic evaluation test set.
Operational Profile (OP)
What is it?
An operational profile is a quantitative, probabilistic description of how a software system is used in its real operating environment. It captures distinct tasks or operations along with their likelihood of occurrence, and is used to guide testing, improve reliability, and prioritize resources.
Why does it matter?
In AI evals, a common question is how to tell whether an evaluation is actually useful. One of the easiest mistakes to make is building a test set that is not representative of real-world usage.
In statistical terms, this means the distribution of the test set differs significantly from the distribution of production traffic.
Taken to an extreme, it is always possible to construct (manipulate) a test set consisting only of easy questions and achieve a score of 100/100. But that score is meaningless as it fails to predict how the system will behave after release.
Operational profiles also help answer a harder question: what is a reasonable threshold of eval metric(s) for release decisions? If the test set reflects real-world usage, thresholds can be interpreted as acceptable failure rates. This is ultimately an SLA or SLO decision that should be defined in the product requirements document.
Orthogonal Defect Classification (ODC)
What is it?
Orthogonal Defect Classification is a structured method for classifying software defects along multiple independent dimensions. The goal is to turn defects into actionable signals about process weaknesses, rather than treating them as simple bug counts.
Why does it matter?
It is already clear from the definition why ODC is a useful concept for AI evals. ODC is a step forward from error analysis. As AI systems become more complex, individual failures often stem from multiple contributing factors. By classifying defects along orthogonal dimensions, AI evals can better surface risk patterns, guide mitigation strategies, and support release decisions, instead of merely reporting aggregate scores.
Learn from the past

What I have listed above are not the only software testing concepts relevant to AI evals. Many of these ideas were developed decades ago, long before today’s AI hype, yet they remain surprisingly relevant.
Starting something new from scratch is always exciting. But when building AI evals, it is often more useful to look back and learn from what software engineering has already figured out the hard way.
Beyond specific concepts, software testing has accumulated decades of practical experience and lessons learned. I will share some of those insights in a separate post.
Want to go deeper on AI evals?
We cover AI Evals in much more depth in our AI Evals and Analytics Playbook course, where we share practical guidance on getting stakeholder buy-in, evaluation-driven development, using evals for release decisions, and connecting evals with post-release analytics.
Our next cohort starts Feb 21 and will be our last fully live cohort, with the next one not running until May.
🗓️ If you would like to learn more or see if it is a good fit, feel free to book a call with us here.
🎁 Newsletter subscribers receive a 35% discount (code: DSxAI) for the Feb 21 cohort.

Love this - so many older frameworks apply well to today. I knew some of these but not all. The issue of AI systems having issues from multiple contributing failures is so true. Have you seen any good tactical resources for moving from error analysis to more comprehensive Orthogonal Defect Classification?