
Evaluate Accuracy of LLM-powered Products
Lessons from Trying (and Struggling) to Measure the Right Thing

Hey there! This is the second post in my series on evaluating LLM-powered products, part of my ongoing effort to rediscover what data science means in the AI era. If you're interested in this topic, subscribe to get updates!
I’d love to hear your thoughts, experiences, or even disagreements. Drop a comment below, or reach out on LinkedIn. Let’s keep learning and figuring this out together!
Coming from a statistics background and years in data science, my first thought when asked to evaluate a model is to look at “accuracy”, or related metrics like precision, recall, and F1 score.
So when I began working with LLM-powered products, I naturally asked: What’s the accuracy? But that quickly led to a trickier question: What does accuracy even mean in this context?
What is Accuracy?
In traditional ML, accuracy is simple: if the expected output is True and the model predicts True, it’s correct. But AI products aren’t that simple.
Take this example:

Question: What’s the temperature today?
Expected Output: 110°F
AI Response: Today’s temperature is 110°F.
This response is factually correct—even if phrased differently.
Now consider a more open-ended query:
Question: How’s the weather today? Should I go out and play soccer?
Here, correctness becomes subjective. The “right” answer depends on interpretation, context, and tone. There may be multiple acceptable outputs.
Define What Matters
Accuracy or correctness isn’t always the most important metric. It depends on your product.
For a support bot, factuality and correctness may be critical.
For a creative writing assistant, fluency, tone, or style may matter more.
Like any data science project, defining the right metrics starts with your stakeholders. Work with Subject Matter Experts (SMEs) to translate business expectations into measurable criteria.
Call it accuracy, correctness, factuality, or faithfulness—what matters is alignment on what “good” looks like.
Accuracy Is Use Case–Specific
There are many open-source benchmarks for evaluating LLM accuracy. But they’re often generic and won’t reflect your specific use case.
If you’re building a customer support chatbot, for example, you want to evaluate responses to your customers’ questions—not general trivia or MMLU benchmarks. This requires crafting your own test set. Dataset curation or generation deserves its own post!
How to Measure Accuracy
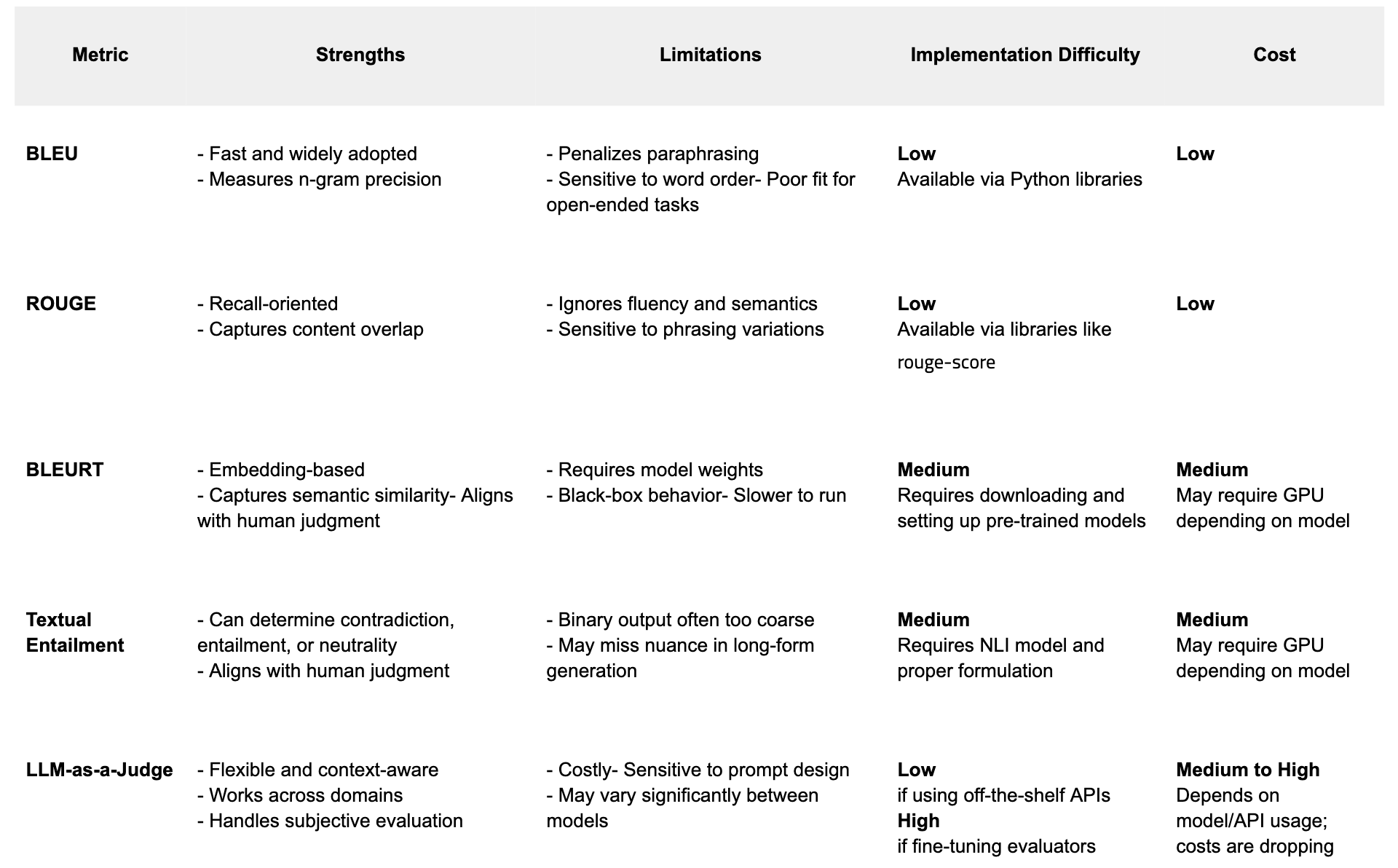
I started with BLEURT and textual entailment, but quickly found their limits—penalizing synonyms, ignoring fluency, and often diverging from human judgment.
That’s when I shifted to LLM-as-a-judge: using a model like GPT or Claude to evaluate the quality of another model’s output.
Some teams fine-tune evaluators; others (like me) use off-the-shelf models with prompt-based scoring. Tools like DeepEval help streamline this.
A typical setup:
Provide the input, model output, and reference.
Ask the LLM to identify factual errors or omissions—guided by evaluation steps or “rubrics.”
Score or classify the response.
Prompt quality matters. I can’t say enough about the importance of collaborating with SMEs to design proper prompts to reflect what evaluators should look for.
A sample accuracy evaluation prompt could look like the one below. You’ll likely need to tweak this—just like any prompt engineering.
prompt_template = """
🧠 Answer Correctness Evaluation
Task:
Rate the assistant's answer based on how correct it is given the question and context.
Criteria:
Correctness (1–5) — Does the answer factually align with the provided context and directly address the question?
Steps:
1. Read the question and context.
2. Check if the answer is factually correct and relevant.
Question: {question}
Context: {context}
Answer: {answer}
Score (1–5):
"""Alternatives & Considerations
There are variations of LLM-as-a-judge. One example is PoLL (source), which aggregates scores from multiple LLMs rather than relying on a single model.
LLM-as-a-judge is easy to implement and increasingly affordable. But it’s not flawless. I highly recommend this Substack from my friend Kriti on When Can You Trust an LLM to Judge Another?
Single-Turn vs. Multi-Turn Conversations
Factuality and correctness are easiest to assess in single-turn interactions. You can create “golden pairs”, which are prompts with verified answers.
Compared to single-turn, multi-turn conversations are closer to natural human conversations. However, multi-turn evaluation is much harder. It requires full dialogue scripts and ground truth references for each turn, which can be expensive and time-consuming to curate. That’s why most evaluations focus on single-turn scenarios.
But we shouldn’t ignore multi-turn performance. Recent research (source) shows that LLMs often struggle with multi-turn dialogues. In fact, studies report up to a 39% drop in performance when conversations go beyond the first few turns, as models tend to “get lost” after early mistakes.
Okay, that’s all on accuracy for this post. Everything I share here comes from things I’ve tried and experimented with. I definitely don’t have all the answers. This field is evolving fast, and I’m learning alongside everyone else. If you’ve been working on the same problem, or have different approaches, questions, or critiques, I’d love to hear from you! This field is evolving fast, and the more we exchange ideas, the better we all get at building and evaluating LLM-powered products.
This series from Data Science x AI is free. If you find the posts valuable, becoming a paid subscriber is a lovely way to show support! ❤

This was a great read! I’ve been wondering about the best ways to evaluate LLMs. I experimented with several LLM-Modulo approaches but was not met with much success. I’ll try implementing the LLM-as-a-judge technique and see if it works better. Thanks for sharing, Stella.