
From Evals to Analytics
Understanding What Really Happens After Deployment

Don’t forget to come and join us on 9am PT Thursday (Oct 23) for a free lightning session Bring AI Evals to Product Leadership! We will share how to carry out the first step in building a solid AI Evals practice - team alignment. Let’s talk about how to have that conversation, and how to influence effectively.
Now everyone’s talking about AI Evals. It may sound like AI Evals can solve all the challenges in our AI products. But Evals is a vague term, and we often mean very different things when we use it.
Let’s clarify what Evals actually are, and more importantly, why Evals alone aren’t enough to build great AI products.

Evals are offline tests
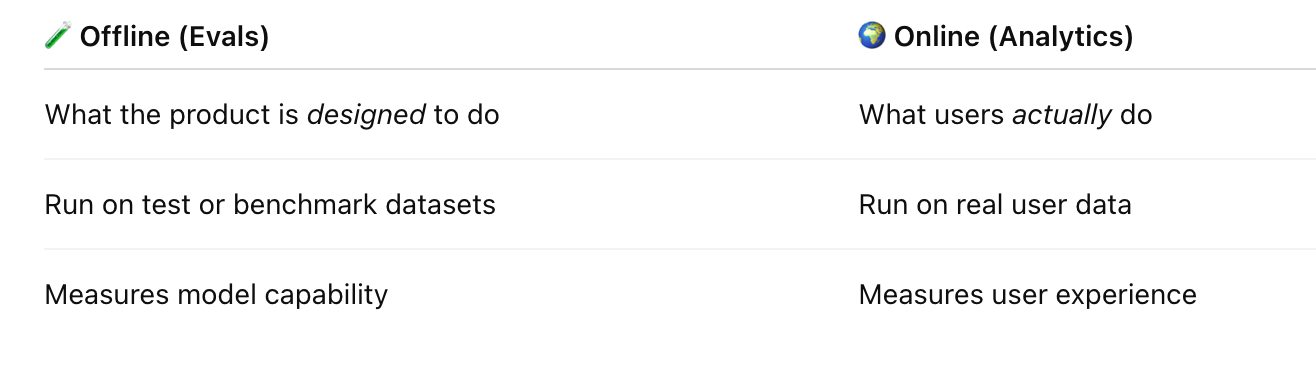
The widely accepted view is that Evals are modularized, offline tests run before deployment or release, i.e. the QA/QC layer of your AI product.
Just like unit tests in software engineering, you need good test coverage before shipping. But instead of testing modules in the codebase, Evals test dimensions or tasks of the AI product behavior.
Evals are run offline on curated or synthetic datasets. Each dataset, together with its metric and rubric, is designed for a specific task.
Evals ≠ Analytics
Offline testing ≠ Online observation
Once we clarify the definition of Evals, the differences between Evals and Analytics become clear:
Now you may ask -
Is analytics just the online version of evals?
No. Analytics can do what Evals cannot.
Extracting Product Insights from Analytics
Evals is controlled, isolated, predictable.
And analytics tackles the messy, multi-turn, real-world reality of how people actually use your product.
E.g. 1 Multi-turn user interaction sessions
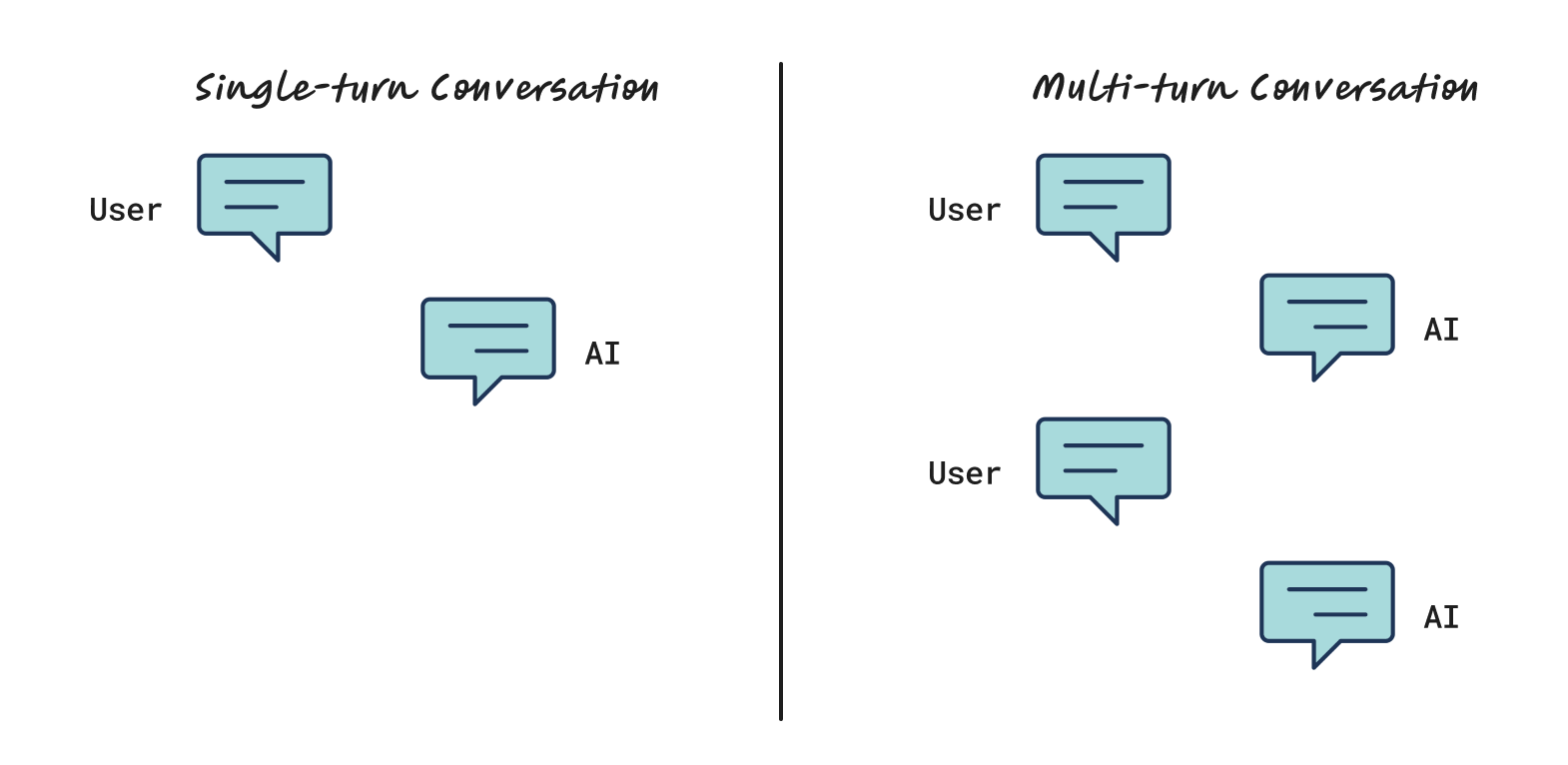
Take chatbots as an example. Most Evals only cover single-turn conversations, because multi-turn datasets are harder to generate and those metrics take longer to run.
But in reality, user-bot interactions are rarely single-turn. Once your product is live, you can analyze real conversation sessions to uncover things Evals can’t:
Where users get stuck or confused
How often they rephrase or retry
When they drop off or escalate to a human
📝 This applies to non-conversational AI too, e.g. copilots, recommender systems, design assistants, and etc. In these products, “sessions” may mean a chain of refinements, generations, or tool interactions.
(For more on multi-turn vs. single-turn, checkout my previous post here.)
E.g. 2 User behavior metrics
Analytics also helps you capture how users feel and behave:
💭 Explicit feedback: thumbs-up/down, comments, ratings
💡 Implicit feedback: sentiment/pattern inferred from language, tone, or behavior
📚 Topic or task analysis: what users are trying to accomplish in each session
When combined with real-time monitoring and system health metrics, these insights give you a full picture of your AI product and its users. Just to list some examples:
🧩 User sentiment + task analysis → reveals what makes users happy/unhappy
🐞 Task analysis + escalation rate → points to product bugs or UX gaps
📊 #Tasks per session → shows how users actually use your product
In short, analytics captures how users iterate, explore, and correct your system, i.e. the human side of the feedback loop.
That’s the real magic: turning Evals + Analytics into a continuous feedback loop, the key to transforming good AI models into great, user-centered AI products.
Our course AI Evals & Analytics Playbook is starting soon (Oct 27)! Enjoy the 50% discount (code: DSxAI), and join us for live, interactive sessions! Build your own Evals and Analytics playbook from pre-release testing to post-release monitoring and analytics in 2 weeks!

Data Science x AI is a free series sharing practical insights on AI evaluation. If you find the posts valuable, becoming a paid subscriber is a lovely way to show support! ❤