
Measuring Compliance In AI Products
Does your LLM product do what you tell it to do?

Hey there! This is the 5th post in my series on evaluating LLM-powered products, part of my ongoing effort to rediscover what data science means in the AI era. If you're interested in this topic, subscribe to get updates!
I’d love to hear your thoughts, experiences, or even disagreements. Drop a comment below, or reach out on LinkedIn. Let’s keep learning and figuring this out together!
A couple years ago, prompt engineering was all the rage. The goal was to craft precise prompts to ensure an LLM followed your instructions exactly. As models grew more capable, prompting seemed less important. Smarter models appeared easier to guide with plain language.
But do LLMs now follow instructions perfectly with simple prompts? The answer is NO. You’ve probably seen it yourself in ChatGPT or Claude. Research also confirms it:
Reasoning can hurt compliance – This study from May 2025 found that chain-of-thought prompting can sometimes reduce instruction-following accuracy, especially when multiple or compositional constraints are involved. The reasoning process can distract the model from the original task.
Instruction hierarchies are fragile – Another paper (from Feb 2025) showed that LLMs often fail to respect priority between layers of instructions (e.g., system-level vs. user-level), even when explicitly told which takes precedence.
If the underlying models aren’t guaranteed to be compliant, how can we be sure our LLM products are doing what we intend? That’s where compliance evaluation comes in.
What is Compliance
In the LLM context, compliance means:
The degree to which a model’s output fully satisfies the explicit and implicit instructions it was given, including constraints on content, format, and scope.
It’s about doing exactly what was asked, no more, no less, and doing it consistently.
Compliance becomes even more critical in agentic designs. Imagine managing a team where one member ignores instructions occasionally, the entire team effort can fail! The more agents involved, the greater the risk that at least one will go off-track.
How compliance is measured in LLMs
There are different ways to measure compliance:
Human judgment – Evaluators score outputs against instructions.
Automated checks – Code validates schema, length limits, banned words, etc.
Benchmarks – Datasets like Super-NaturalInstructions, FollowBench, and AlpacaEval.
LLM-as-a-judge – A trusted model evaluates adherence, producing a compliance rate.
How compliance can be measured in LLM products
After reading my previous posts, you should know by now that open benchmarks won’t work for your specific use case. Human judgement is too time consuming and therefore not a cost-effective solution if you need to run evaluations repeatedly during development.
I use LLM-as-a-judge. Like other pre-deploy evaluations in this series, you’ll need to curate your own dataset: think through the real-world use cases your users face and build a representative test set.
Unlike accuracy like metrics, you often don’t need ground truth answers. Instead, define evaluation rubrics for the judge model, which essentially is a step-by-step guide to tell LLM evaluator what to look out for during scoring.
An LLM-as-a-judge Example:
System prompt of your product:
You are a legal document summarizer.
- Always produce a bullet-point summary of exactly 5 items.
- Each item must be under 15 words.
- Do not include any personal names.
- If the input is not a legal document, respond with "Not applicable".Evaluation steps for LLM-as-a-judge:
Count bullet points.
Check length of each point.
Ensure no personal names.
If non-legal, confirm exact output “Not applicable”.
Pass only if all checks succeed.
With this setup, your dataset can include both legal and non-legal inputs, and the judge model determines whether the rules are followed. Over time, you can track compliance rates and catch regressions before they reach production.
More Complicated Scenarios
The above is a simple example. In real-world scenarios, expectations for compliance can get complicated quickly. For example, you may want an AI tutor bot to respond directly and clearly when users ask about syllabus details or homework due dates, but avoid giving direct answers to problem-set questions. These different expectations should all be covered in compliance evaluations. To achieve this, you may need to categorize entries in your test set and assign different evaluation steps accordingly.
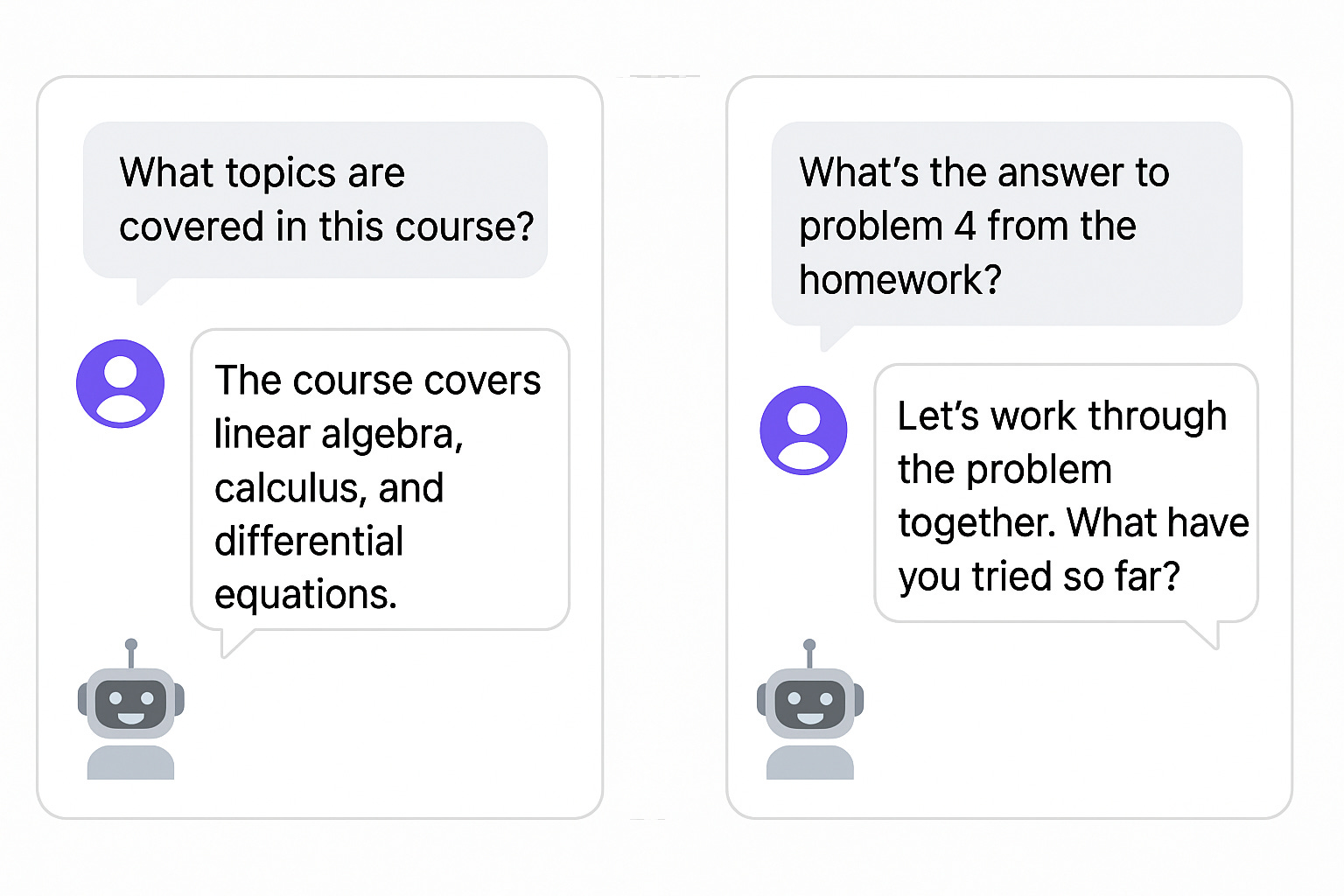
Use LLM-as-a-judge With Caution
One thing to watch out for: always test your evaluation steps (a.k.a. rubrics). Writing these steps for LLM-as-a-judge is, in itself, a form of prompt engineering. There’s a risk that the evaluator model might not fully follow the evaluation criteria you’ve defined. Frameworks like DeepEval include components such as GEval to help manage the prompt engineering for evaluation, but it’s still essential to have human subject-matter experts periodically review and validate the evaluator’s outputs before scaling up.
This series from Data Science x AI is free. If you find the posts valuable, becoming a paid subscriber is a lovely way to show support! ❤
