
Why & What to Evaluate
LLM-powered Products v.s. LLMs

Why
You may find this too obvious—of course we need to evaluate LLMs. We need to know how models perform in reasoning, in math, in agentic coding (replace all developers—yea?), and also in cost, latency, and security. And yes, there are already many companies and research groups diligently publishing model performance rankings.
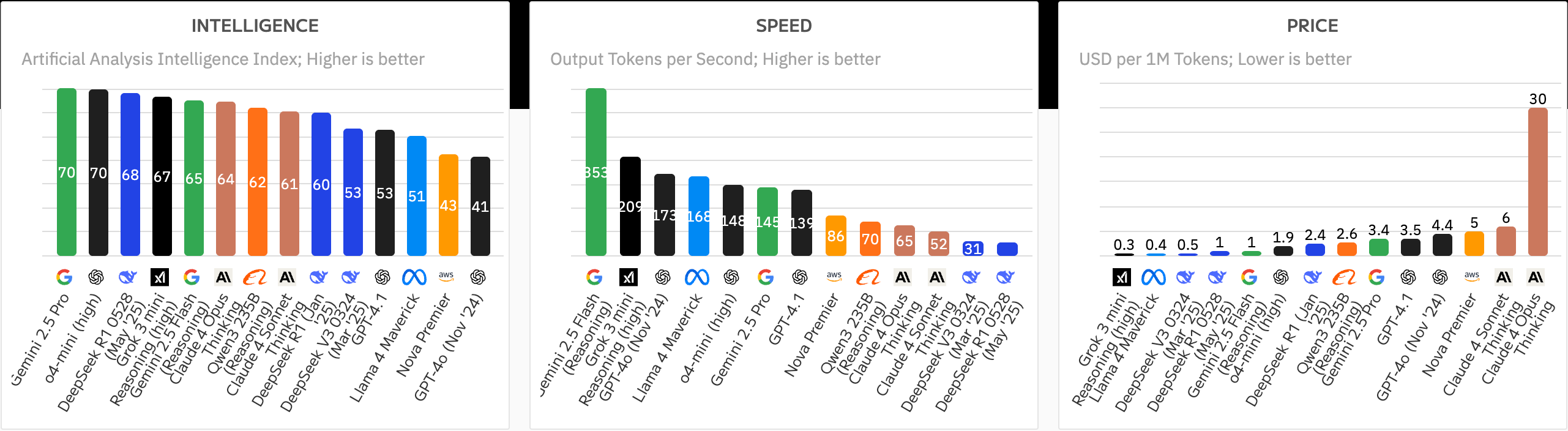
So why do I still worry about it?
Because there is a gap—often a big one—between how a language model performs in isolation and how an LLM-powered product behaves in the real world.
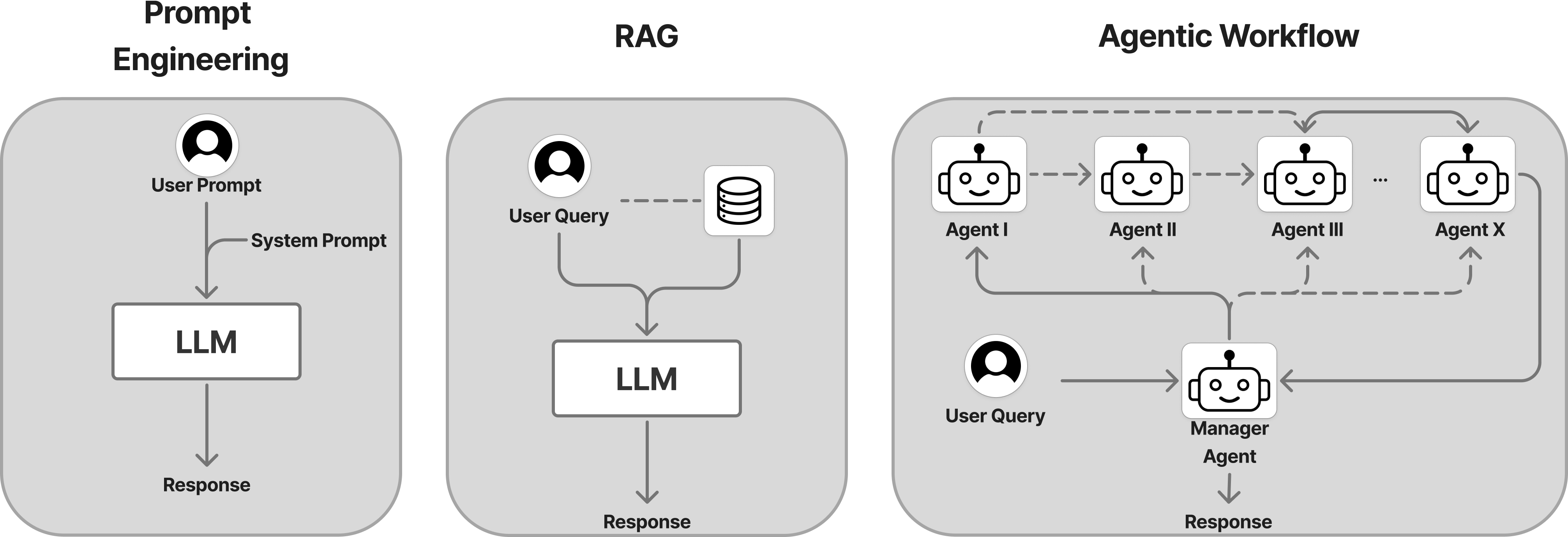
The first wave of LLM-powered applications largely relied on prompt engineering—crafting carefully worded inputs to steer the model's output without changing the model itself. Then, around early 2023, we saw the rise of Retrieval-Augmented Generation (RAG) and later, multi-RAG systems, which allowed applications to pull in external knowledge sources at query time to enhance relevance and factuality. More recently, in late 2023 and 2024, the focus has shifted toward agentic workflows—systems that break down user goals into multi-step plans and execute them autonomously using tools and APIs.
If prompt engineering wasn’t unpredictable enough to set applications apart from the models they were built on, RAG certainly introduced more uncertainty. Imagine a customer support chatbot powered by the latest frontier LLM but connected to an outdated knowledge base. Or a student-facing AI tool linked to a biased and error-prone dataset. In both cases, the underlying model might score high on every leaderboard, but that doesn't guarantee the product is useful, safe, or even coherent. A powerful LLM does not automatically ensure a powerful AI product.
And agentic workflows? Oh my. These often involve multiple language models, large and small, wired together with intricate prompts and instructions to interact with external tools. It’s like running a human team with members of varying experience levels—each with a role to play. You’d check in on their progress, track their coordination, and review the quality of their work. You need to do the same with agents too.
Beyond the evolving tech stack adding more complexity, there’s another reason to go beyond leaderboard metrics: those benchmarks are built on open-source datasets for generic use cases. But your use case is likely very specific. If you work in student financing, for example, you need to ensure the chatbot doesn't quote exact scholarship amounts without human review and auditing—a mistake that could lead to legal and reputational issues. If you're in e-commerce, you want to make sure your bot reliably communicates up-to-date promotions and stock availability. Model-level performance doesn’t guarantee product-level reliability in your context.
What
Now, let’s talk about what to evaluate.
First, a quick disclaimer: what I’ll share here is by no means a comprehensive list of evaluation metrics. The right metrics can vary widely depending on your use case, industry, and even user expectations. That said, I want to share the metrics I’ve personally worked with, and some lessons I’ve learned along the way.
One of the first evaluation frameworks I came across when I entered this field was Stanford’s HELM framework—Holistic Evaluation of Language Models. Their foundational paper, published in November 2022 (link), proposed a multidimensional view of evaluation. Instead of just focusing on accuracy, HELM emphasized the importance of seven categories: accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency. This framework helped set the tone for thinking about language model performance not just in terms of output quality, but also trustworthiness and impact.

Though the HELM framework was designed for evaluating language models themselves, it remains a valuable reference point when thinking about LLM product evaluations. That said, metrics for LLM-powered products can and should be very different from those used for the underlying models. Once you move from model to application, you're no longer just measuring generation quality or toxicity—you’re now measuring usefulness, reliability, and alignment with specific user goals.
In the next few posts, I’ll dive deeper into evaluation metrics—especially those I’ve worked on in real-world settings—and share what I’ve learned along the way. I’ll also touch on the often overlooked but critical topic of dataset curation for use case–specific or domain-specific evaluations.
Stay tuned.
This series from Data Science x AI is free. If you find the posts valuable, becoming a paid subscriber is a lovely way to show support! ❤
