
AI Evals: Lessons to learn from Software Testing
Now it's time to start Evaluation Driven Development

In my last post, I outlined several concepts from software testing that map directly to AI evals. If you missed it, you can read it here.
I also promised I would follow up with something more practical: what we can learn from decades of software testing practice.
A great place to start is Brian Marick’s 1997 essay, “Classic Testing Mistakes.” Nearly 30 years later, the themes still feel uncomfortably relevant.
Marick grouped common testing mistakes into 5 themes with detailed explanations. In this post, I’ll cover the first 3 themes and reinterpret them in the context of AI evals today. In the next post, I’ll discuss the remaining 2 themes, along with a few additional mistakes I’ve seen repeatedly in AI evaluation practice.
Let’s begin.
Theme 1: The Role of Testing
… most organizations believe that the purpose of testing is to find bugs.
AI evals probe system behavior across different scenarios. If your goal with AI Evals is to find bugs, you will not be disappointed. You are guaranteed to find as many issues (edge cases) as you want. But an infinite list of rare failures does not tell you how the AI system behaves in production. Real users are not red teamers. They follow predictable workflows, operate under time pressure, and exhibit patterned behavior.
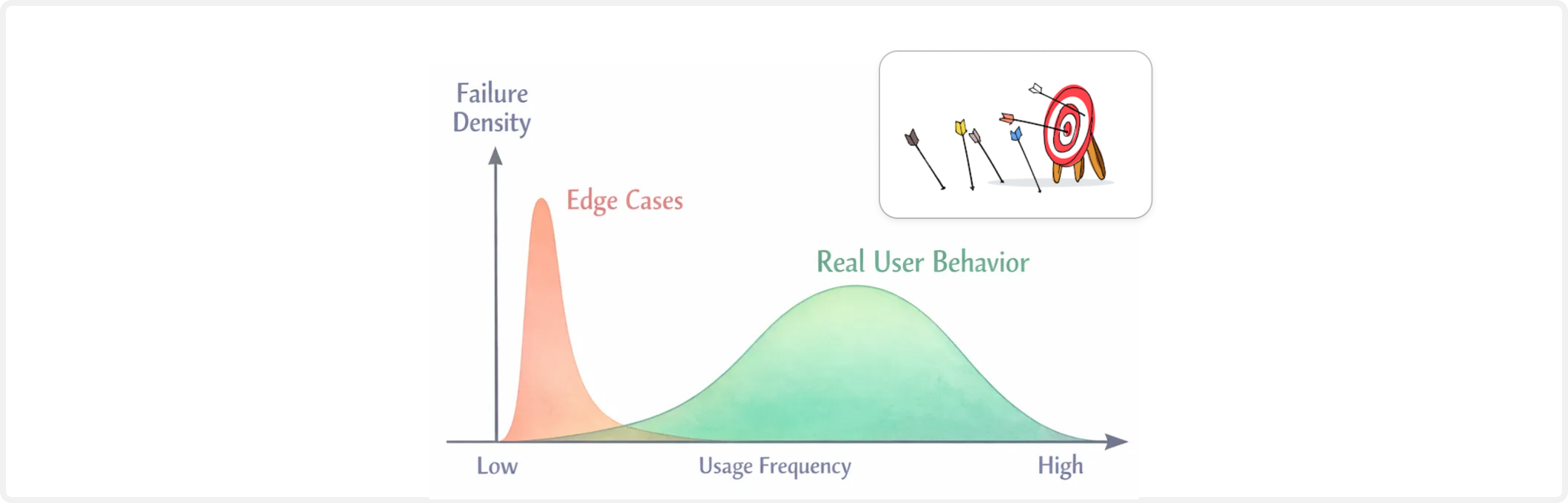
The goal of AI evals is not to maximize discovered failures. It is to understand risk under realistic usage distributions. That means focusing on operational profiles, failure severity, and frequency, rather than collecting isolated examples of model misbehavior.
Finding bugs is easy. Characterizing production risk is harder, and far more important.
Theme 2: Planning the Testing Effort
It’s not unusual to see test plans biased toward functional testing.
We still see this bias in AI evals. Teams test features and components in isolation: retrieval quality, tool accuracy, routing. Each piece works.
What’s often missing is usability and workflow-level evaluation. Does the system fit into real user behavior? Are outputs understandable? Do users trust it appropriately? Functional correctness does not guarantee product viability.
Putting stress and load testing off to the last minute…
We sometimes get too excited about our AI product, especially with agentic systems.
Agent architectures look elegant on whiteboards. Workflows are decomposed into sequential or independent tasks, each handled by a specialized agent. Engineering teams divide and conquer.
Then, right before release, reality hits: compounded latency, low throughput and increasing error rates across agents makes the end-to-end system painfully slow and unreliable. No normal user would tolerate it.
In multi-agent systems, stress and load testing should drive design, as they are architectural constraints.
Beware of an overreliance on beta testing.
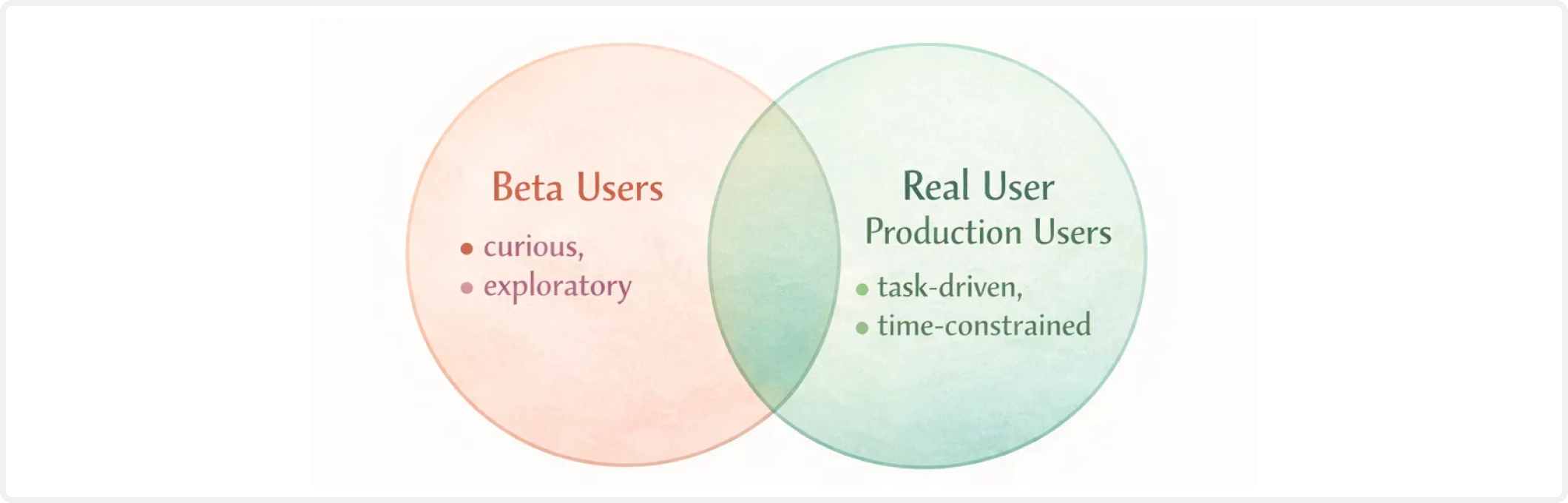
As Marick noted, beta users rarely behave like the real user population. They experiment. They churn quickly. If the experience is subpar, they move on without filing a bug report.
Many AI teams skip offline evals and jump straight to beta pilots, hoping for fast feedback. But with AI products, it is even harder to get explicit feedbacks or signals from users. Beta testing without careful planning and monitoring is not a substitute for evaluations.
Feedback is useful. Unstructured exposure is not.
Planning matters in AI evals just as much as it did in 1997.
Theme 3: Personnel Issues
Be especially careful to avoid the trap of testers who are not domain experts.
Domain experts may be hard to find. Try to find a few. And hire testers who are quick studies and are good at understanding other people’s work patterns.
This one deserves emphasis.
Today, evaluation work is often owned by a single PM or a developer who happened to draw the short straw. Subject matter experts are rarely deeply involved. As a result, AI evals default to generic metrics: hallucination, toxicity, latency.
Those matter. But they are not what defines success in domain-specific products.
In vertical AI products, construction, legal, accounting, healthcare, the real risks are domain-specific failure modes. When SMEs are absent from eval design, teams optimize for generic metrics and miss the actual pain points users care about.
All testers will be hampered by a physical separation between developers and testers. A smooth working relationship between developers and testers is essential to efficient testing.
I’ve experienced the tension myself. Engineers ask, “Why do you need all these implementation details?”
Because modern AI systems are architectural systems. If I do not understand how the system is built, I cannot reason about what could go wrong.
Evaluation design depends on system design.
Consider a text-to-SQL system, where natural language queries are translated into SQL. Suppose we want to evaluate PII leakage.
If raw database records contain un-redacted PII and you rely on prompt instructions to remove PII in the generated response, then leakage becomes a model-behavior problem. You must design guardrail scenarios and run systematic PII leakage evals.
But if you implement a deterministic preprocessing step that redacts PII before the SQL generator ever sees the data, the risk shifts. Now you test the preprocessing pipeline, not the model output.
The evaluation strategy changes because the architecture changes.
I’ll pause here since this post is getting long.
In the next post, we’ll cover the remaining two themes - The Tester At Work and Technology Run Rampant. I’ll also share a few additional AI evals pitfalls that mirror classic software testing mistakes in the next post.
If you’ve enjoyed reading about AI evals and want to go deeper, we cover these topics much more systematically in our AI Evals & Analytics Playbook course.
Our next cohort starts Feb 21 and will be our last fully live cohort, with the next one not running until May.
🎁 Newsletter subscribers receive a 35% discount (code: DSxAI).

The point about "characterizing production risk" vs. just finding bugs resonates deeply. It's the same shift unit testing brought to software — from ad hoc debugging to structured, repeatable quality gates.
One thing I'd add: the feedback loop speed matters enormously here. Just like developers need fast test runs to iterate confidently, AI teams need quick eval cycles to iterate on prompts and model changes without flying blind. That's actually what pushed me to build EvalSense (evalsense.com) — a framework that brings unit-test-style pass/fail assertions to LLM outputs so teams can gate on quality in CI/CD.
Looking forward to the next post on "Technology Run Rampant" — that one feels especially timely for agent-heavy architectures.